


My First Data Engineering Project from Scratch

Are you interested in building a data engineering project from scratch, but not sure where to start? Look no further! In this blog post, I'll share my experience working on my first data engineering project and the lessons I learned along the way.
Introduction
At the end of 2022 I made the decision that I wanted to make a "career switch" from being a Cloud Native Engineer to becoming a Data Engineer.
I had made a rough roadmap for myself on how I thought I could make the switch. I first studied for and passed the DP-900 Azure Data Fundamentals exam and right away started studying for the DP-203 Azure Data Engineering exam. I quickly noticed that my SQL was too rusty and I missed a solid base of knowledge and experience with Python.
After asking for advice and looking around on the internet I decided to do the Data Engineering with Python Career Track from Datacamp, but before I could start that one I first completed the SQL Fundamentals, Python Fundamentals and Python Programming Skill Tracks. All tracks are short videos explaining a subject and then you have to practice it with hands-on exercises. I really enjoyed the Datacamp courses and I would recommend them to anyone who wants to learn (more about) SQL, Python and Data Engineering.
Instead of focussing on the DP-203 exam I decided I wanted to first get more hands-on experience with SQL and Python. So, I started working on my first data project and wanted to make sure that I use different data sources and data formats to extract, transform and load.
Project Purpose
For my first data engineering project, I wanted to build a project to gain hands-on experience with Python and SQL, but also use it for my portfolio.
The question was, what data am I going to use? You can get data everywhere for free to use for your data project, but I wanted to have my own data. A couple of months ago I placed hygrometers in several rooms in the house, which measure the humidity and temperature. That is when I came to the idea to gather and use the humidity data and I wanted to combine it with outside weather data and my electricity + gas usage and get some insights out of it.
The projects main focus is to extract, transform, and load the data into a PostgreSQL database.
Tools and Technologies
Cloud Services
My expertise and experience is working with Azure with regards to Cloud providers. So this project uses the following Azure Services:
Azure Storage Account
Azure PostgreSQL
Programming Language
One of my goals/ The purpose was gaining hands-on experience with Python and SQL in a Data Engineering project it is no surprise that I used Python as main language for this project.
Data Platform
I did not want to make the setup to complex for my first project, because one of the goals is to gain hands-on experience with Python and SQL. I chose Github Action Workflows to run the Data pipelines, because of my experience with Github and Github Actions.
Versioning
I chose Github as tool for running the Data pipelines, so the most logic choice is to also use Github for versioning.
Project Setup
Directory Structure
The projects structure is:
.github/workflows: This directory contains the Github Workflows.
More information about the specific workflows can be found in the Workflows section.
/data: This directory contains the CSV file with humidity data.
/etl: This directory contains the code for the ETL process. It contains:
__init__.py: This file initialises the
etlpackage and import modules from the/etldirectory.constants.py: Contains all the variables used across the project.
humidity_data_etl_pipeline.py: Contains the user-defined functions specific to transforming the humidity data.
utils.py: Contains generic user-defined functions used across the project.
weather_data_etl_pipeline.py: Contains the user-defined functions specific to transforming the weather data fetched from weather API.
/scripts/bash: This directory contains a Bash script that uploads the CSV file to an Azure storage account.
requirements.txt: This file contains the Python packages that are required to run the project.
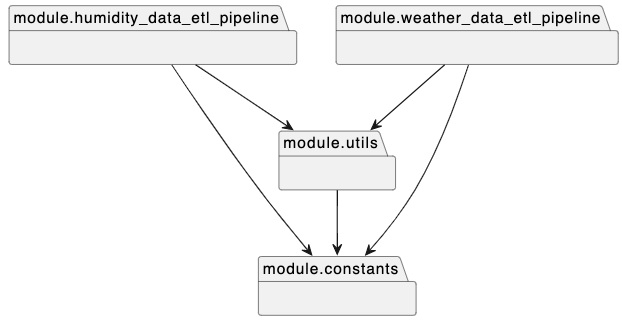
Package
In the etl package I have different modules, the diagram below shows the dependency between the modules.
Workflows
The project has four workflows:
codeql-code-analysis.yml: This workflow runs semantic code analysis against the repository's source code to find security vulnerabilities.
flake8-lint.yml: This workflow runs the flake8 linter on the Python code in the /etl directory. It runs:
On demand/ Manually
With a pull request
On push to the main branche
humidity-data-etl-pipeline.yml: This workflow extracts, transforms, and loads the humidity data from the uploaded CSV file into the Azure PostgreSQL database. The workflow uses the constants and functions defined in the /etl directory. It runs:
On demand/ Manually
upload-humidity-data.yml: This workflow executes the Bash script located in the /scripts/bash directory, which uploads the CSV file to an Azure storage account. It runs:
On demand/ Manually
weather-data-etl-pipeline.yml: This workflow fetches weather data from a weather API, transforms the data using the constants and functions defined in the /etl directory, and loads the data into the same Azure PostgreSQL database as the humidity data. It runs:
On demand/ Manually
Data Engineering Processes
ETL Process
For this project I used the ETL process, which is a combination of three processes:
Extract
Raw data is extracted from one or multiple sources
E.g. JSON, XML, CSV, Relational databases
Transform
The raw data is being adjusted to the organisations requirements
E.g. Converting data types, Cleaning data, Combining data
Load
The data that has been transformed can be made available to users
E.g. Written to a database/ data warehouse.
For my project it is a pretty simple overview as you can see. I have (for now) two data sources that provide raw data (CSV and JSON), and with the use of Github Workflows I run data pipelines to extract the data, transform it and write it to a PostgreSQL database
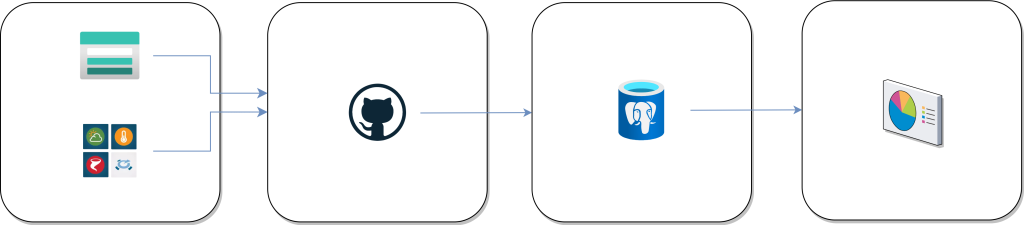
Extract
The two datasources are:
An Azure Storage Account which will have a CSV uploaded with the Humidity data from my living room
A weather API that provides data in JSON format
Azure Authentication
To be able to fetch a file from the storage account I need first authenticate. I used the DefaultAzureCredential class from the azure.identity package.
######################
# Basic example code #
######################
# Install the azure identity package
pip install azure-identity
# Import the DefaultAzureCredential Class
from azure.identity import DefaultAzureCredential
# Create credentials object
credential = DefaultAzureCredential()The DefaultAzureCredential relies on the environment variables:
AZURE_CLIENT_IDAZURE_CLIENT_SECRETAZURE_TENANT_ID
Azure Storage Account
To connect to my storage account I used the BlobClient class from the azure.storage.blob package.
######################
# Basic example code #
######################
# Install the blob package
pip install azure-storage-blob
# Import the BlobClient Class
from azure.storage.blob import BlobClient
# Get BlobClient object
account_url = "https://" + storage_account_name + ".blob.core.windows.net"
storage_container_name="example_container"
blob_name="example_blob"
credential = DefaultAzureCredential()
blob_client = BlobClient(
account_url,
container_name=storage_container_name,
blob_name=blob_name,
credential=credential
)
# Download the blob
blob_content = blob_client.download_blob()Weather API
To get data from an API we can use the Requests HTTP library.
######################
# Basic example code #
######################
# Install Requests
python -m pip install requests
# Import Requests
import requests
# Get the response object
response = requests.get('https://exampleapi.com/api')Transform
CSV
To be able to transform the CSV data I used Pandas DataFrame.
######################
# Basic example code #
######################
# import pandas dataframe
import pandas as pd
# Convert a csv to a dataframe
df = pd.read_csv(blob_content)Response object
In my case the weather API returned JSON, so we can use the built-in JSON decoder from the Requests library. Like with the CSV data I converted the JSON object into a Pandas Dataframe.
######################
# Basic example code #
######################
# Get the JSON object from the response object
json_response = response.json()
# Convert to a dataframe
df = pd.DataFrame(json_response)Load
PostgreSQL
For my project I am using an Azure PostgreSQL Database, so I am using Psycopg to connect to the instance. Psycopg is the most popular PostgreSQL database adapter for the Python programming language.
######################
# Basic example code #
######################
# Install Psycopg
pip install psycopg2
# Import Psycopg
import psycopg2
# Create a connection object
conn = psycopg2.connect(
host=host,
user=user,
password=password,
dbname=dbname,
sslmode=sslmode
)
# Create a cursor to execute PostgreSQL command
cursor = conn.cursor()
# Execute a PostgreSQL command
cursor.execute("""
SELECT * FROM {};
""".format(table_name))
# Close the connection
cursor.close()
conn.close()Lessons Learned
Before I start to write any code:
Write unit test during the development process
Write data quality checks during the development process
What's up next?
In the project I have added a TODO.md with tasks I still want to implement.
After this first time project I will start working on different setups, using the same data, but using tools like Airflow, Mage, Azure Data Factory, Azure Synapse, Azure Databricks, PySpark etc. This way I can get more hands-on experience with different tools and technologies.
So keep an eye on my blog and/or LinkedIn Posts!
References
Fundamentals of Data Engineering by Joe Reis & Matt Housley
Hi Mustafa, I have not done the exam yet. A colleague of mine did the exam with only going through the learn material. He said the learn material was enough.